数据隐私是什么?
什么是数据隐私?在云计算环境中用户的数据隐私即为秘密数据,是不想被他人获取的信息。
以下场景可能会导致数据隐私泄露:
- 个人信息和外部数据库结合查询
- 个人信息被收集以增加商业价值
- 敏感信息未有安全存放,数据在存储和查询阶段可能会泄露
根据属性是否能标志出个人以及是否敏感,数据可分为以下这四种类别:
- 标志符:可以唯一标志出用户,如手机号、驾驶证号
- 准标志符:无法唯一标志,但能用来和外部数据库关联定位,如性别、年龄
- 敏感属性:如薪水
- 非敏感属性
数据生命周期和隐私保护技术
在大数据的各个生命周期中,大数据面临着各种外泄风险,提出的数据隐私保护技术多种多样,原理从数据匿名到加密技术不等,具体如下:
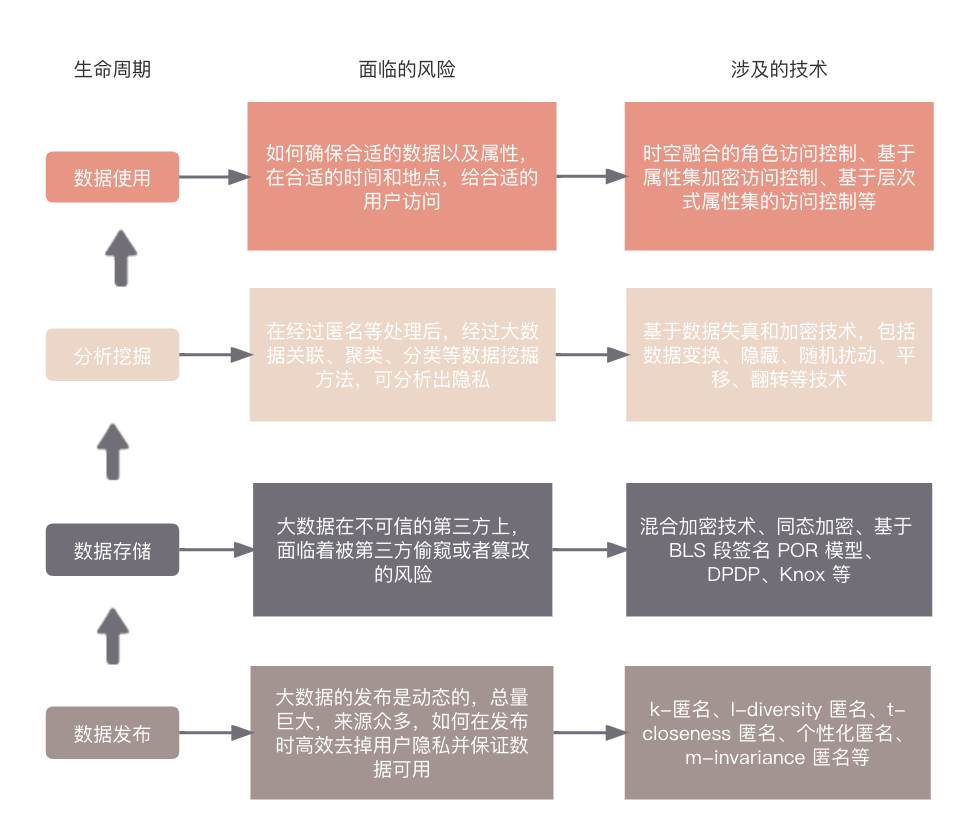
匿名技术(Anonymization):
是数据隐私保护最常用的技术之一,目的是去除唯一标志性,可以在数据存放到数据库前或者使用前执行。包括:
- 移除或者忽略个人信息,包括标志符和准标志符
- 假名化(Pseudonymization):通过使用加密技术生成新的字符来替代原标识符(通常为直接标识符),包括可逆假名化(可以从加密数据中获取原来的明文数据)、不可逆转假名化(无法从加密数据获取原来的明文数据)
- 根据准标注符分组、聚合或分类
重识别攻击(Re-identification Attacks)
即便已经移除了标志性信息,还是能重新定位到用户身份。
例子1:一家流行在线电影供应商公布了一个用户和电影评选结果数据库。为 了保护客户身份,供应商会用随机编号替换客户名称,并删除个人详细资料。安全研究人员发现,通过综合分析数据与互联网电影数据库中公开的信息,可以揭露许多个人用户的身份。这项研究使我们充分认识到数据匿名化不只是将数据库中的字段简单地删除。
例子2:在美国 Massachusetts , 69% 的公开登记选民信息可以通过出生日期和邮编定位识别出来。
为改进数据匿名化,对抗重识别攻击,提出了 K-Anonymity 和 L-Diversity 技术。
K-匿名化(K-Anonymity)和 L-多元化(L-Diversity)
目的是让试图识别数据的人们难以区分每项记录和其他 k-1 条记录。为了实现 K-匿名化,一般会对数据做以下处理以进行分组:
- 压缩:用 ‘*’ 替代信息
- 泛化:用边界信息或者范围信息替代具体内容,如年龄 28 可以重新分组到 ‘<30’
K-Anonymity 要求在经过以上操作之后,每个以准标志符分组的组别有 k 个示例。
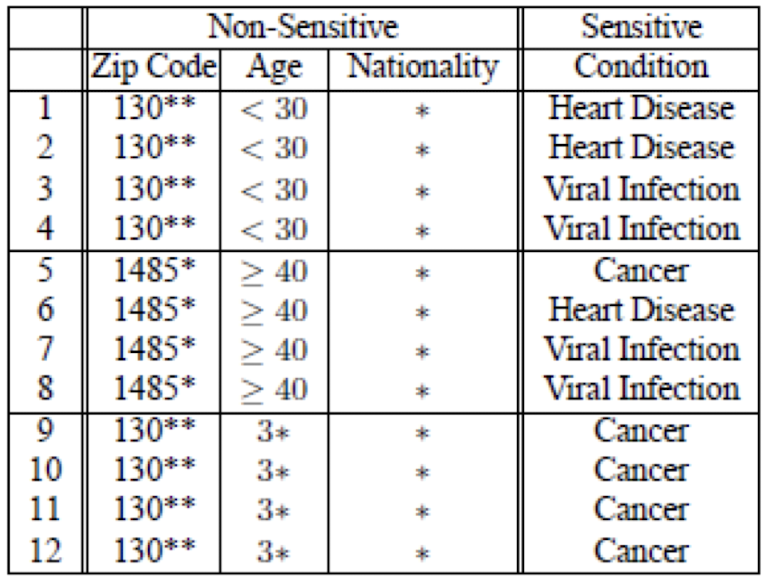
以病人信息举例,原始信息如下:

对邮编后两位和国籍使用压缩,对年龄使用泛化,得到 4-Anonymity 分组数据如下:
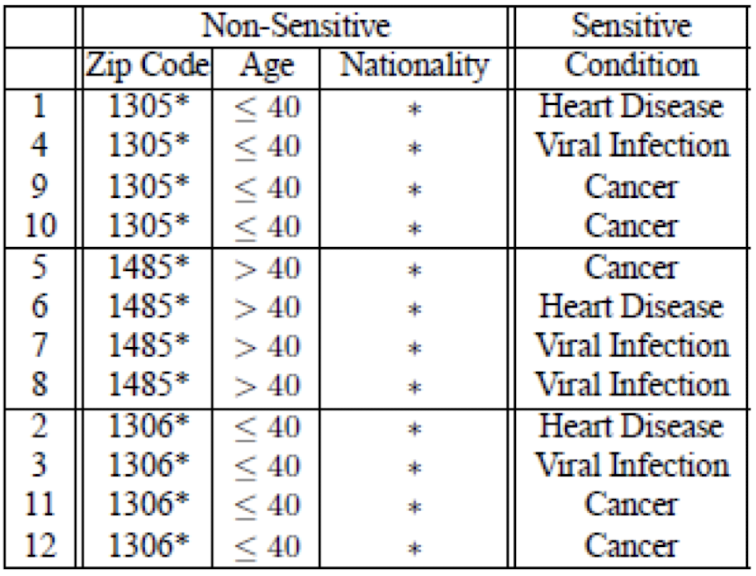
L-Diversity 要求每个准标志符的分组的敏感信息的类别大于 L 个。
进一步地,改成对邮编最后一位和国籍使用压缩,对年龄使用泛化,得到 2-Diversity 分组数据如下:
大数据加密技术
1. 加密存储
Lin H Y等人于2012年提出了一种针对HDFS(Hadoop分布式文件系统)的混合加密技术,该技术将对称加密和非对称加密进行了融合。当有新的隐私数据文件需要加密时,先通过非对称加密方法(AES或RC4)对该文件内容进行快速加密,并将其分布式存储于每个HDFS节点上,然后使用对称加密方法对用于加密该文件内容的密钥进行加密,并将结果存储于该数据的头文件中,以此提供对密钥的有效管理。
该方法的缺点在于在获取数据出来计算和将数据存储到 HDFS 都需要加解密操作,会造成很大的时间开销。
2. 可搜索加密
如果数据已经是以加密的形式存储在云端,将数据从云端拉取再解密再进行搜索则会非常耗时。可搜索加密技术是搜索技术和加密技术的结合,可在数据加密上云之后实现根据关键字检索的功能,有些可搜索加密方案更能实现范围查询或布尔查询等高级检索功能。
大数据挖掘保护技术
分类结果隐私保护
- 对数据进行随机扰动,对于原始数据X1,X2,…,Xn,将其看成满足特定分布的随机变量X,为了隐藏原始数据值,在每个原始值上添加一个服从随机分布Y的随机数Y1,Y2,…,Yn,则扰动后的数据为X1+Y1,X2+Y2,…,Xn+Yn的形式,记为Z;
- 然后对数据进行恢复,数据恢复即已知随机变量分布Y、Z以及X+Y=Z的关系,用Y、Z的值估计X的过程,应用贝叶斯公式可以得到原始数据估计的迭代方程,从而得到原始数据的近似X’;
- 最后是分类过程,得到了原始数据的模糊近似X’之后即可应用普通的分类方法,如利用决策树对数据进行分类,降低分类的准确度
聚类结果隐私保护
首先是对原始数据进行几何变换,以对敏感信息进行隐藏,然后是聚类过程,经过几何变换后的数据可以直接应用传统的聚类算法(如K近邻)进行聚类
数据匹配
何时会用到数据匹配?
典型的数据需求场景与数据使用方式有以下几种:
- 同业之间,联合同业数据提升数据总量,进行联合反欺诈、运营效率提升等,比如银行与银行之间;
- 第二类:跨行业,例如银行在做反欺诈的过程中,需要其他的行业提供数据支持,打通行业间数据,拓宽数据维度,进行营销、反欺诈、运营等建模;
- 第三类:个人到机构,指机构需要采集个人终端各类信息进行相关的业务应用,像APP可能会采集个人的一些行为数据,但是基于隐私保护,部分字段无法采集,这就是个人到机构的数据应用;
- 第四类:机构整合数据源,一些机构或参与方通过把各方数据源的数据进行整合,参与到数据交易市场里面去交易。
传统数据匹配技术
- 明文匹配:对于非敏感数据,可直接明文匹配。
- 哈希匹配:先对数据进行加密隐去敏感信息再进行数据匹配,但数据发送方仍然可以知道对方取走了哪些交集数据,仍然存在安全风险。
- 第三方可信平台对接:通过一个公信的第三方协调数据资源,比如大数据交易平台,但需要考虑安全和效率上的平衡,并且需要经过安全评估以及审核的流程。
联邦学习
联邦学习是密码学和人工智能相结合的分布式学习技术。它是一种可以保证在本地原始数据不出库,只通过传输中间结果(模型的梯度信息和模型参数)进行信息交换完成联合训练机器学习模型的方法。随着大数据和人工智能的快速发展,逐渐形成了横向联邦、纵向联邦和联邦迁移三个分类。
横向联邦
每个参与方都有对应标签和相应特征,类似于分布式计算,几方合力去计算出一个模型,去预测、跑批,最后产生相应的结果,对每一方的数据要求比较苛刻;
纵向联邦
产出模型的那一方有标签,但特征可能很少或者说没有,通过利用其他方的数据来作为特征,训练出一个整体的模型,来让外部数据产生它相应的价值。
联邦迁移
在双方的用户与用户特征重叠都较少的情况下,利用迁移学习来克服数据或标签不足的情况。
Reference:
- 大数据隐私保护技术综述
- 为何有时匿名数据没有匿名
- 利用数据匿名化增强云计算安全(英特尔)
- 隐私保护计算那些事儿
- 隐私计算开源现状
- 什么是联邦学习
- HKUST MSBD 5001 Lecture12
本文由 ellila 创作,采用 知识共享署名4.0 国际许可协议进行许可
本站文章除注明转载/出处外,均为本站原创或翻译,转载前请务必署名
最后编辑时间为: Jan 13, 2023 at 01:45 am